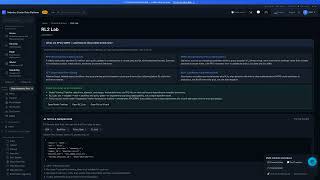
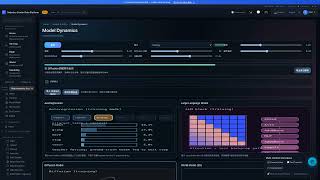
Data Ingestion Pipeline
500+ episodes/hr via API, S3, or fleet streaming.
- Auto schema validation
- Timestamp sync checks
Collect manipulation data, train AI models, deploy to robots — all in one place. The complete operating system for robot learning with 86+ integrated tools.

Episodes live on laptops, NAS drives, and random S3 buckets. Finding a specific failure takes hours, and data organization leaves when researchers leave.
Without frame-level replay linked to joint states, debugging is guesswork. Teams re-collect data for failures they cannot precisely diagnose.
Without experiment tracking and regression testing, every release is a leap of faith. Teams oscillate between versions without confidence.
Read our technical deep-dive: Robot Time Fabric →
Five modular stages sharing a unified data model. Each operates independently.
500+ episodes/hr
Label & tag episodes
GPU clusters or own compute
Model registry & audit trail
Closed-loop feedback
Six domains covering every stage of the robot learning lifecycle.
500+ episodes/hr via API, S3, or fleet streaming.
Label episodes with instructions, keyframes, and tags.
Auto-flag jitter, frame drops, and calibration drift.
Frame-level replay with synced joints and cameras.
Version models with full dataset and config lineage.
End-to-end from dataset curation to deployment.
Benchmark ACT, Diffusion Policy, Octo, RT-2, OpenVLA.
Track hyperparameters, curves, and utilization.
Generate synthetic scenarios from learned physics models.
Drag-and-drop 3D scene editor for simulations.
Describe scenes in natural language, generate 3D environments.
Validate policies in simulation before real-world deployment.
Monitor all robots across facilities from one dashboard.
Schedule, monitor, and manage robot missions in real time.
Low-latency remote control with force feedback and VR support.
Live dashboards for torques, latency, and success rates.
ODD definitions, FMEA worksheets, and safety case templates.
Auto-flag anomalous episodes and cluster by root cause.
ML-based detection of distribution shift and trajectory anomalies.
Benchmark cycle times and A/B test policy versions.
Per-team usage tracking with budget alerts.
Maintenance tickets linked to robots and failure reports.
Full history: calibrations, parts, firmware, inspections.
Runbooks, troubleshooting guides, and best practices.
The operating system layer between your hardware, AI models, and deployed fleet. It connects every piece into a single closed loop.
Every failure in production becomes a data point for the next training cycle — the closed loop that separates improving teams from plateauing ones.
No conversion scripts required for standard formats. Custom formats supported through a pluggable parser API.
| Format | Use Case | Support |
|---|---|---|
| HDF5 | ACT, ALOHA, imitation learning | |
| RLDS | DeepMind RT-X, Open X-Embodiment | |
| LeRobot Parquet | Hugging Face LeRobot, dataset sharing | |
| MP4 + JSON | Video with sidecar metadata | |
| ROS Bag | ROS1/ROS2 recordings | |
| Custom | Proprietary via pluggable parser API |
Three integration paths into your existing stack.
Lightweight ROS2 node streaming topics directly to Fearless. YAML config, auto episode segmentation.
pip install fearless-ros2-bridge
Full programmatic access: upload, create datasets, trigger evals, manage fleets. Type-annotated, async-compatible.
pip install fearless-sdk
OpenAPI 3.1 covering all 86+ operations. TypeScript SDK also available. 1K req/min (Startup), unlimited (Enterprise).
Docs: developers/
Purpose-built for robot learning data. Not repurposed ML tooling.
| Capability | Fearless | Custom Scripts | W&B / MLflow | Scale AI |
|---|---|---|---|---|
| Robot episode replay | ||||
| HDF5 / RLDS / LeRobot native | ||||
| Failure mining & anomaly detection | ||||
| Policy evaluation (ACT, DP, VLA) | ||||
| Fleet deployment monitoring | ||||
| Dataset versioning + hardware lineage | ||||
| Self-hosted / air-gapped |
Built-in Partial / manual Not supported
Start free for research. Scale up when your team and data grow.
$0
For university labs and non-commercial research
$249/mo
For early-stage robotics companies
Custom
For production robotics operations
Versioned datasets, reproducible evaluations, and a single home for your lab's data that outlasts any individual researcher.
Stop spending 40% of engineering time on data pipeline plumbing. Fearless closes the collect-train-deploy loop so you can focus on the product.
Fleet-wide policy performance visibility, systematic failure analysis, and an auditable trail from data collection through deployment.
Works with any robot that produces standard data formats. Buy compatible hardware from our store.

7-DOF research arm
Buy →Precision manipulator
Buy →Collaborative arms
Buy →
Humanoid platform
Buy →
Quadruped robot
Buy →Leader-follower arm
Buy →
Bimanual mobile
Buy →Entry-level arm
Buy →Fearless works with any robot that produces HDF5, RLDS, LeRobot, ROS Bag, or MP4+JSON. Browse full catalog →
108 public robotics datasets — searchable, previewable, and license-classified. Open data you can download and use, plus curated links to everything else.
Find datasets by robot type, task, format, or license tier.
Visualize episodes, camera feeds, and joint trajectories before downloading.
Open-license datasets available for direct download. Format conversion included.
Search and download datasets via MCP tools or REST API from Claude Code, Cursor, or any MCP client.
Yes. Encrypted at rest (AES-256) and in transit (TLS 1.3), logically isolated, never used for SVRC training or shared with third parties. Enterprise can self-host for full data sovereignty. GDPR-compliant with US and EU hosting.
Fearless is robot-agnostic. Any hardware producing standard formats (HDF5, RLDS, LeRobot, ROS Bag, MP4+JSON) works. Tested with OpenArm, Franka, UR5e/UR10e, Unitree G1/Go2, AgileX Piper, Mobile ALOHA, SO-100, and more. Browse hardware.
Yes, on Enterprise. Docker containers with Kubernetes (Helm chart provided). Min: 8-core CPU, 32 GB RAM, GPU recommended. Air-gapped deployments supported.
Native LeRobot Parquet read/write. Push curated datasets to Hugging Face Hub. Retraining triggers invoke LeRobot scripts on your compute or SVRC GPUs. Eval results flow back automatically.
Yes. OpenAPI 3.1 covering all operations. Python and TypeScript SDKs. Included in Startup and Enterprise plans.
Research: 500 GB. Startup: 5 TB. Enterprise: unlimited. A typical ALOHA episode (3 cameras, 50 Hz, 30s) is ~150 MB, so 500 GB holds ~3,300 episodes.
Yes. Automatic topic extraction and conversion on import. Specify topic-to-field mapping in config.
Lightweight ROS2 node subscribing to robot topics, streaming to Fearless. YAML config, auto episode segmentation. Supports Humble and Iron. pip install fearless-ros2-bridge
Native LeRobot and Hugging Face integration. Custom frameworks via standard launcher API — provide a training script, Fearless handles orchestration and tracking.
Yes. Enterprise campaigns include platform access. Data flows directly into your workspace with full metadata and QA reports.
Managed teleoperation campaigns delivering training-ready datasets into Fearless.
OpenArm, DK1, UR series, and more. Purchase or lease hardware.
Technical deep dive on HDF5, RLDS, and LeRobot with conversion examples.
Data collection, teleoperation setup, policy training, and deployment.
21 short tutorials covering the complete platform — from teleoperation to fleet deployment.